
I’m currently a 2nd-year Ph.D candidate at REAL LAB, Zhejiang University, advised by Yongliang Shen. Prior to this, I earned my B.E degree from Chu Kochen Honors College, Zhejiang University (浙江大学竺可桢学院) at 2024.
My research interests focus on AI Agents and LLM Post Training (RL included). My earlier work in 2025 focused on RL for GUI Agents, and my current research investigates Post-Training techniques for General Agents, including agent skills, on-policy distillation (OPD) and reinforcement learning (RL).
📢 I’m actively seeking research-internship opportunities in industry on the topics above. Feel free to reach out if there might be a fit.
🐈 Our lab is also recruiting remote / on-site interns — undergraduate and Master’s students are warmly welcomed! See Join.
🔥 News
- 2026.07: 🔥🔥 Our new work SEED was released, introducing self-evolving OPD beyond SDAR. Featured as 🤗 HF Daily Paper #3!
- 2026.07: 🎉🎉 One paper was accepted by ACMMM 2026.
- 2026.06: 🔥🔥 Our new work OPID and DEAR were released, about OPD.
- 2026.06: 🎉🎉 One paper was accepted by ECCV 2026.
- 2026.05: 🔥🔥 Our new work SDAR was released, featured as 🤗 HF Daily Paper #2!
- 2026.05: 🔥🔥 Our new work SKILL1 was released, featured as 🤗 HF Daily Paper #2!
- 2026.04: 🎉🎉 Four papers were accepted by ACL 2026, see you in San Diego, US.
- 2026.04: 🔥🔥 Our new work SKILL0 was released, featured as 🤗 HF Daily Paper #2!
- 2026.02: 🎉🎉 One paper was accepted by CVPR 2026.
- 2025.11: 🎉🎉 Three papers were accepted by AAAI 2026.
📝 Publications
🤖 Agentic Post Training
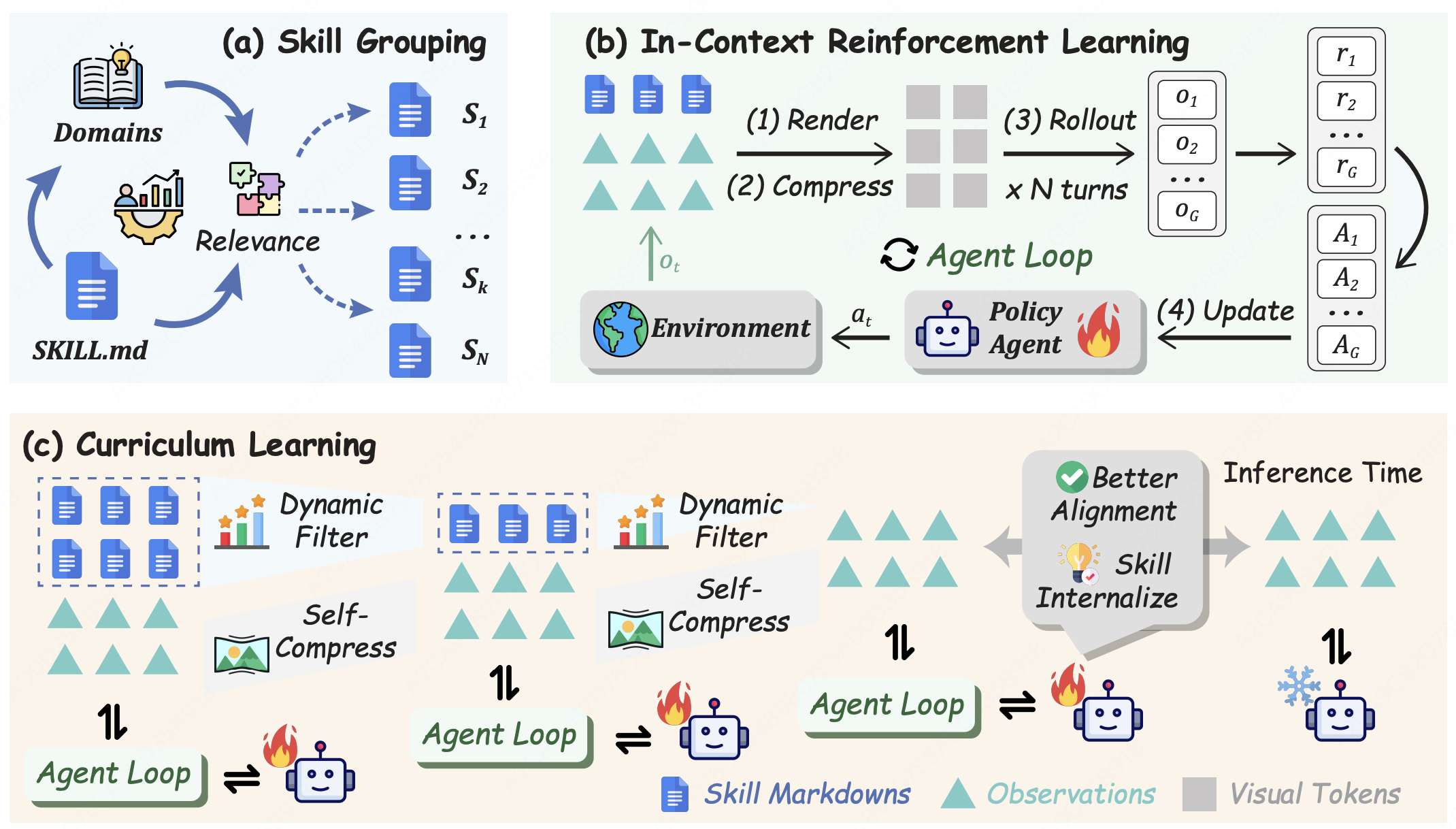
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen
[Paper] |
- We propose an in-context agentic RL framework that internalizes external tool-use skills into the policy itself, enabling agents to retain reusable behaviors across tasks without repeated demonstrations.
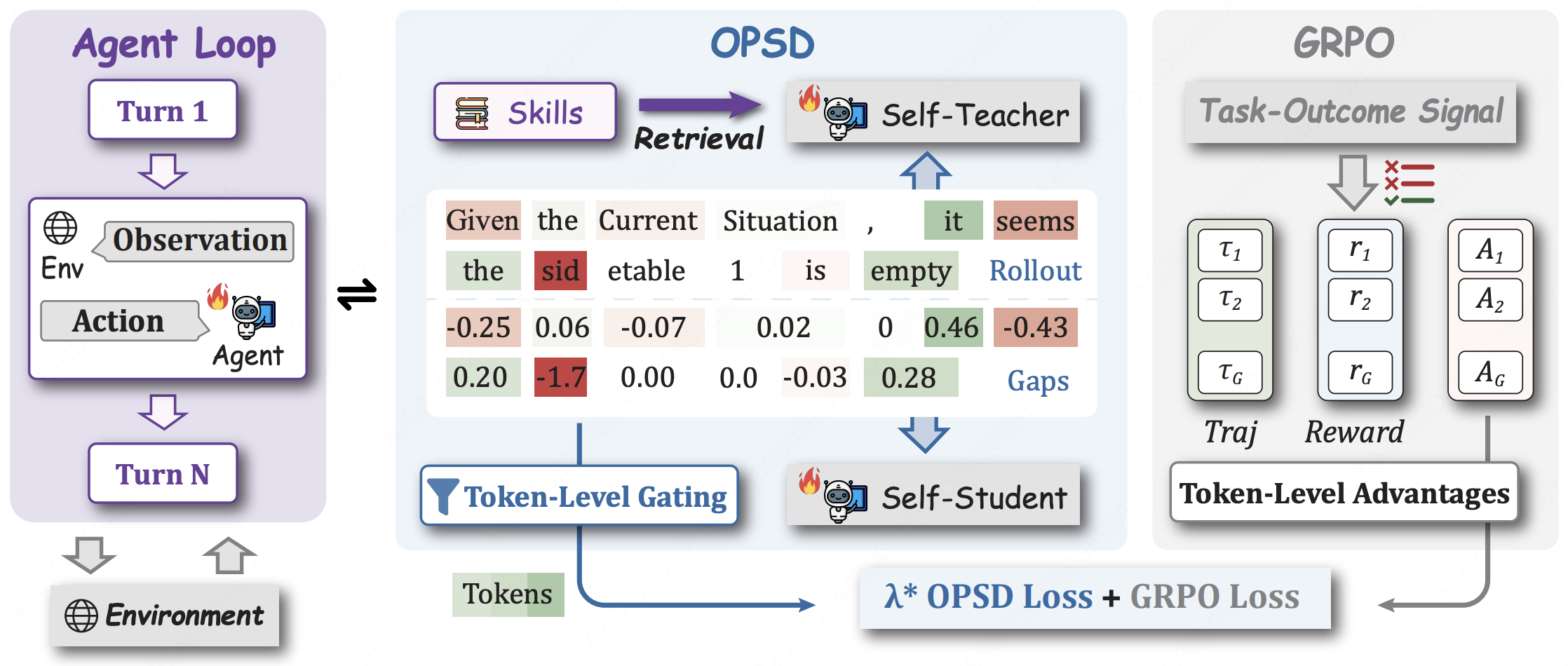
SDAR: Self-Distilled Agentic Reinforcement Learning
Zhengxi Lu, Zhiyuan Yao, Zhuowen Han, Zi-Han Wang, Jinyang Wu, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen
[Paper] |
- A self-distillation pipeline that lets an agent improve through its own high-reward trajectories, bridging on-policy distillation and RL to stabilize long-horizon multi-step training.
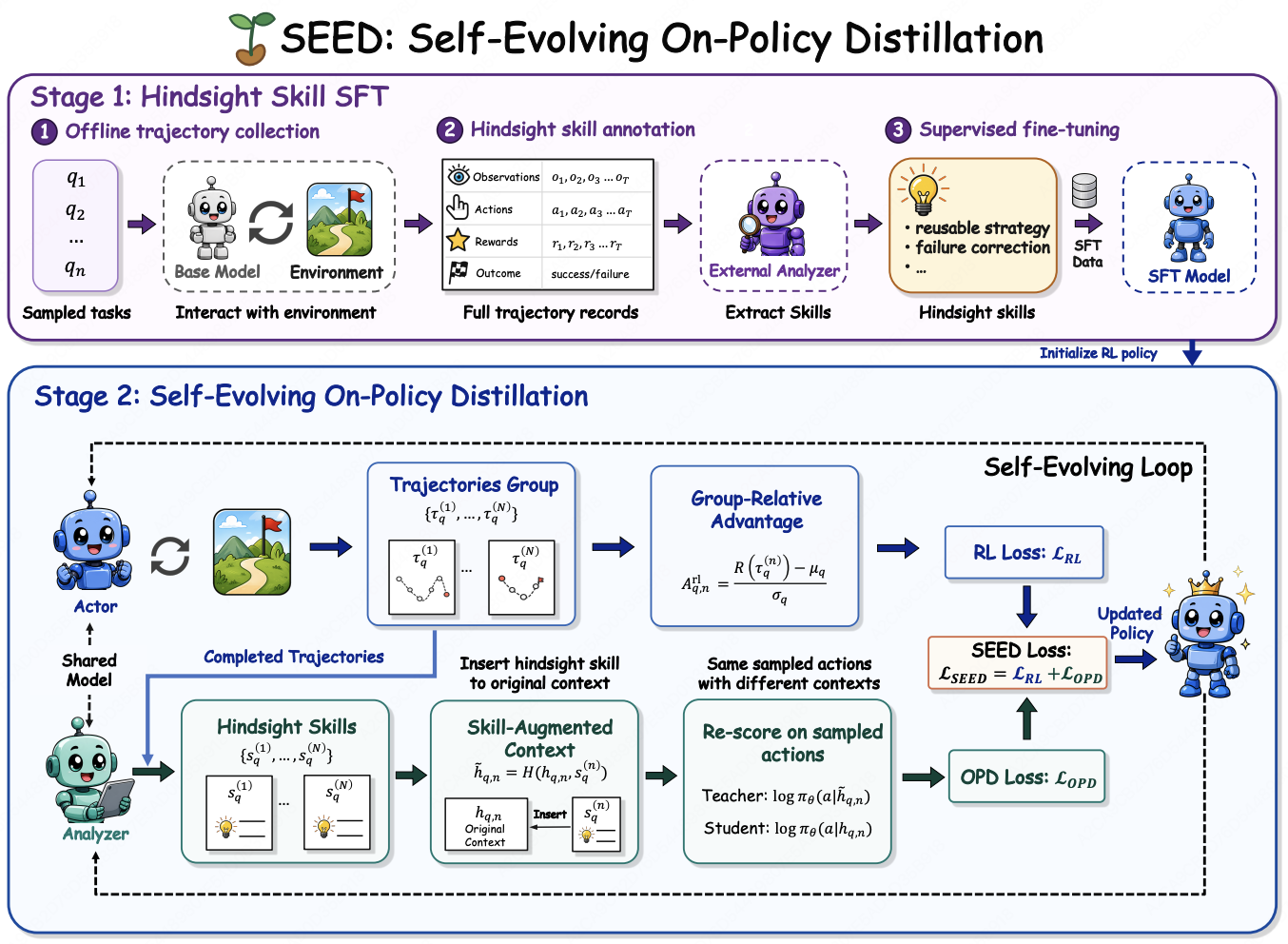
SEED: Self-Evolving On-Policy Distillation for Agentic Reinforcement Learning
Jinyang Wu, Shuo Yang, Zhengxi Lu, Fan Zhang, Yuhao Shen, Lang Feng, Haoran Luo, Zheng Lian, Shuai Zhang, Zhengqi Wen, Jianhua Tao
[Paper] |
- A self-evolving framework where one policy checkpoint plays two synchronized roles — acting in the environment and analyzing its own completed trajectories into natural-language hindsight skills — then distills the skill-induced action-probability shift back into the policy, closing the supervision gap between sparse outcome rewards and token-level learning.
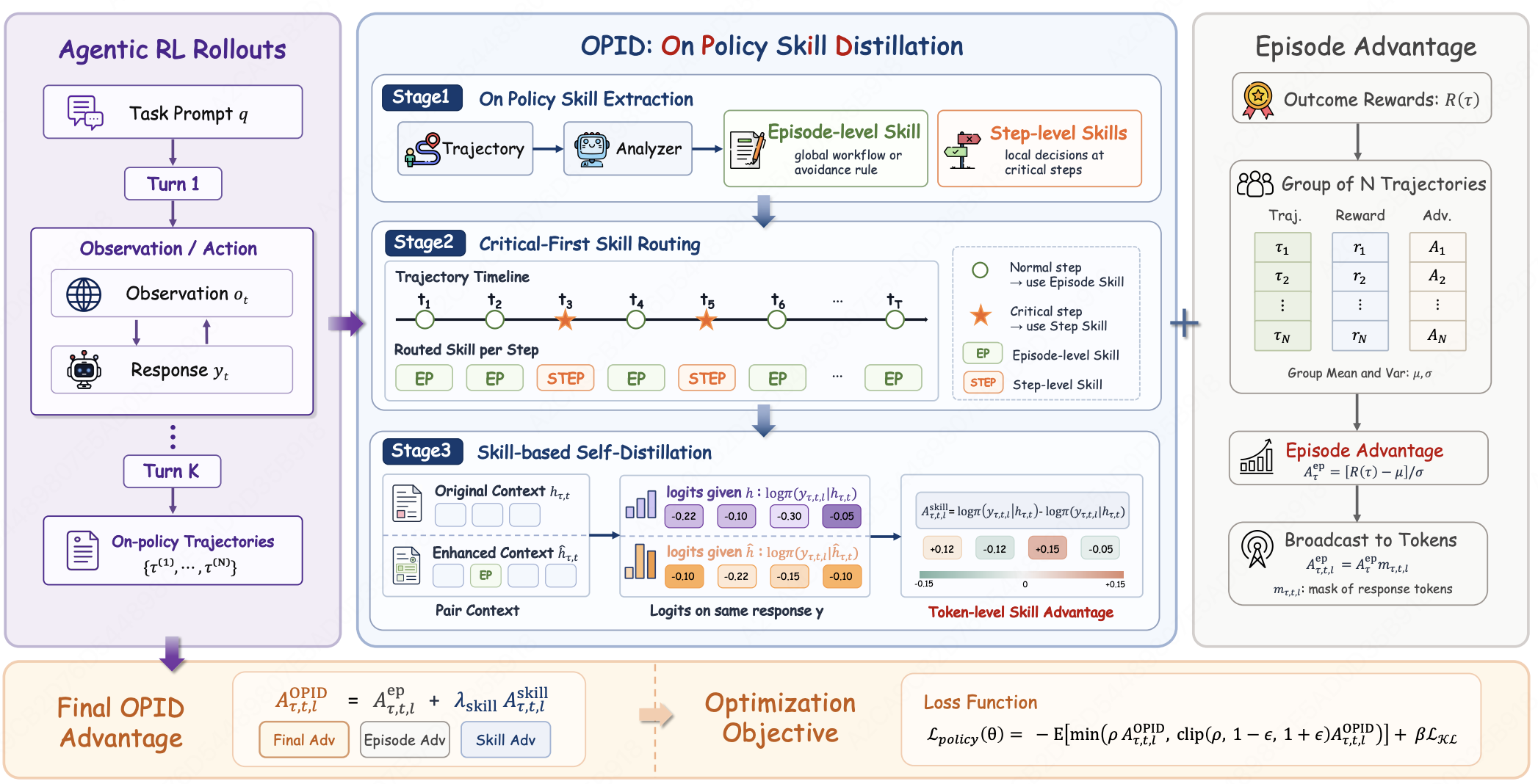
OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
Shuo Yang, Jinyang Wu, Zhengxi Lu, Yuhao Shen, Fan Zhang, Lang Feng, Shuai Zhang, Haoran Luo, Zheng Lian, Zhengqi Wen, Jianhua Tao
[Paper] |
- Extracts hierarchical skill supervision (episode- and step-level) directly from completed on-policy trajectories and injects it back into the interaction history; the log-probability shift between original and skill-augmented contexts yields a token-level self-distillation advantage that complements the outcome reward, providing dense, distribution-matched hindsight supervision without external skill memories.
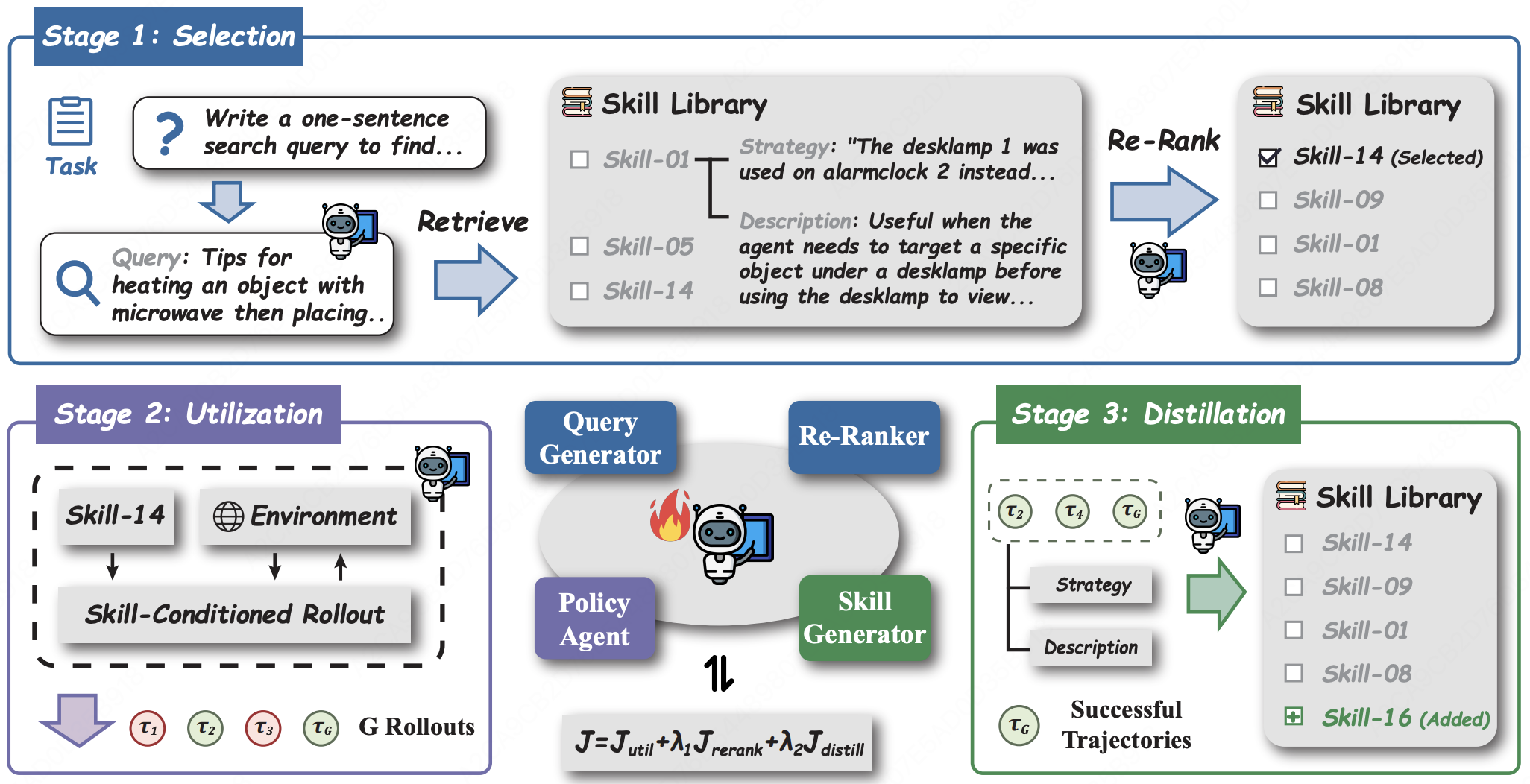
SKILL1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Yaorui Shi, Yuxin Chen, Zhengxi Lu, Yuchun Miao, Shugui Liu, Qi Gu, Xunliang Cai, Xiang Wang, An Zhang
[Paper] |
- Jointly evolves the agent policy and its skill library through RL, allowing newly discovered skills and the controller to co-adapt instead of being optimized in isolation.
- Preprint Finding the Evidence: Discovering Decision-Supporting Tokens for On-Policy Reasoning Distillation, Jinwei Xiao, Zhuowen Han, Yueqing Sun, Zhengxi Lu, Yuxin Liu, Zhiyuan Yao, Wentao Chen, Qi Gu, Xunliang Cai
- Preprint Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles, Jinyang Wu, Guocheng Zhai, Ruihan Jin, Yuhao Shen, Zhengxi Lu, Fan Zhang, Haoran Luo, Zheng Lian, Zhengqi Wen, Jianhua Tao
- Preprint Code-A1: Adversarial Evolving of Code LLM and Test LLM via Reinforcement Learning, Aozhe Wang, Yuchen Yan, Nan Zhou, Zhengxi Lu, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen
📱 MLLM Agents
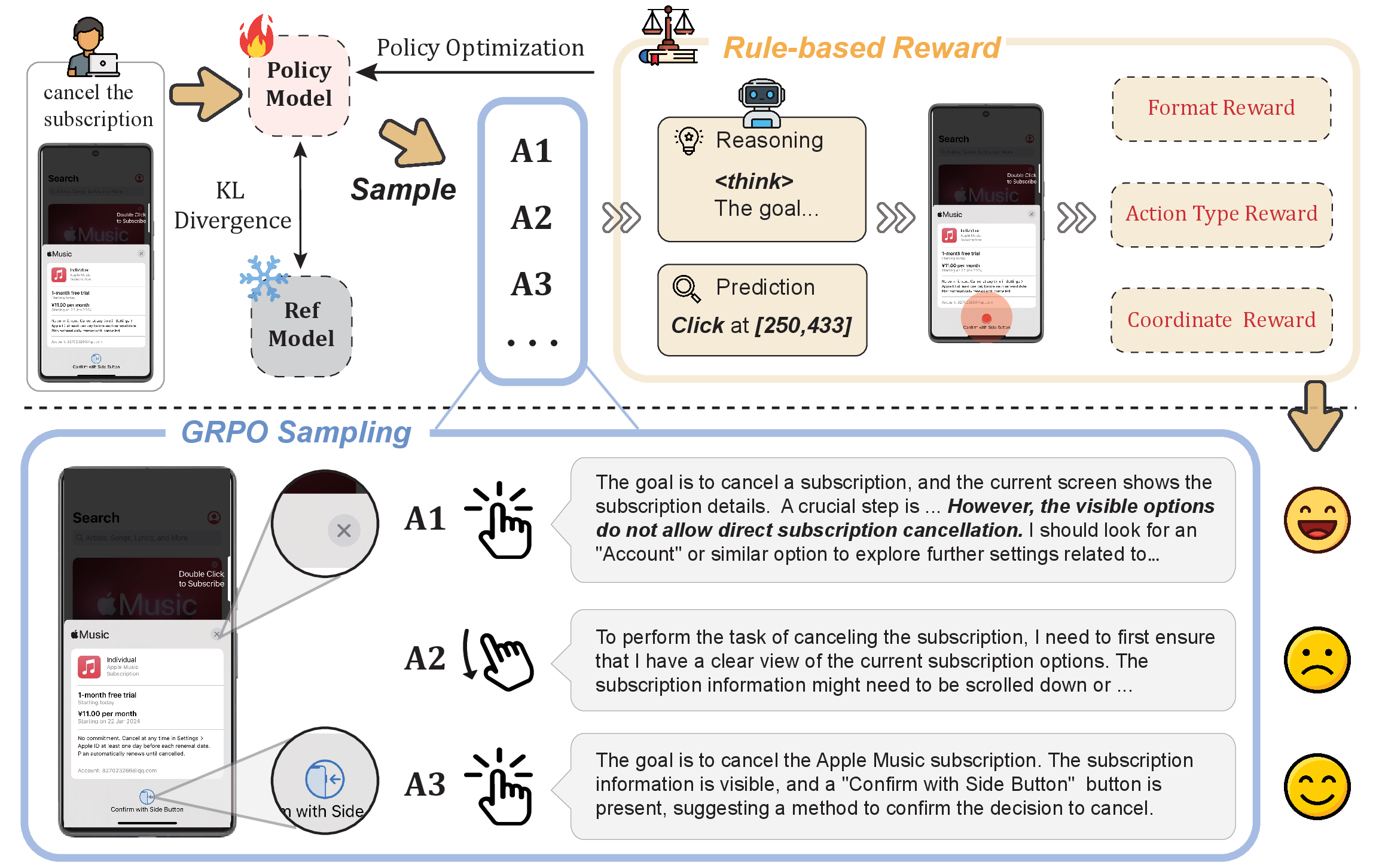
UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, Hongsheng Li
[Paper] |
- The first work to apply rule-based reinforcement learning to GUI action prediction, improving the data efficiency and grounding accuracy of MLLM-based GUI agents.
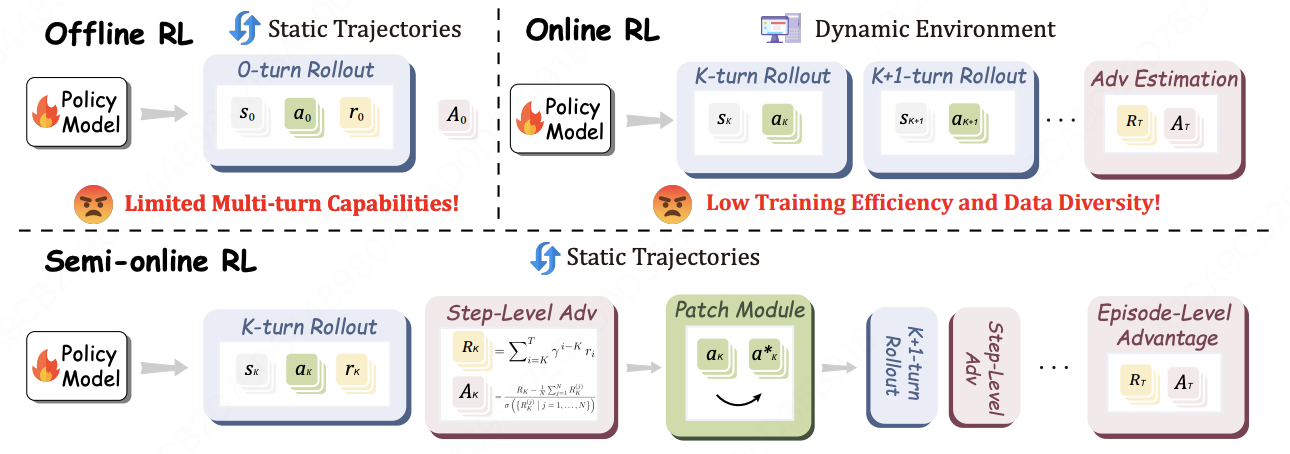
UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
Zhengxi Lu, Jiabo Ye, Fei Tang, Yongliang Shen, Haiyang Xu, Ziwei Zheng, Weiming Lu, Ming Yan, Fei Huang, Jun Xiao, Yueting Zhuang
[Paper] |
- A semi-online RL paradigm that mixes offline trajectories with on-policy rollouts to combine the stability of imitation with the exploration benefits of online RL for GUI agents.
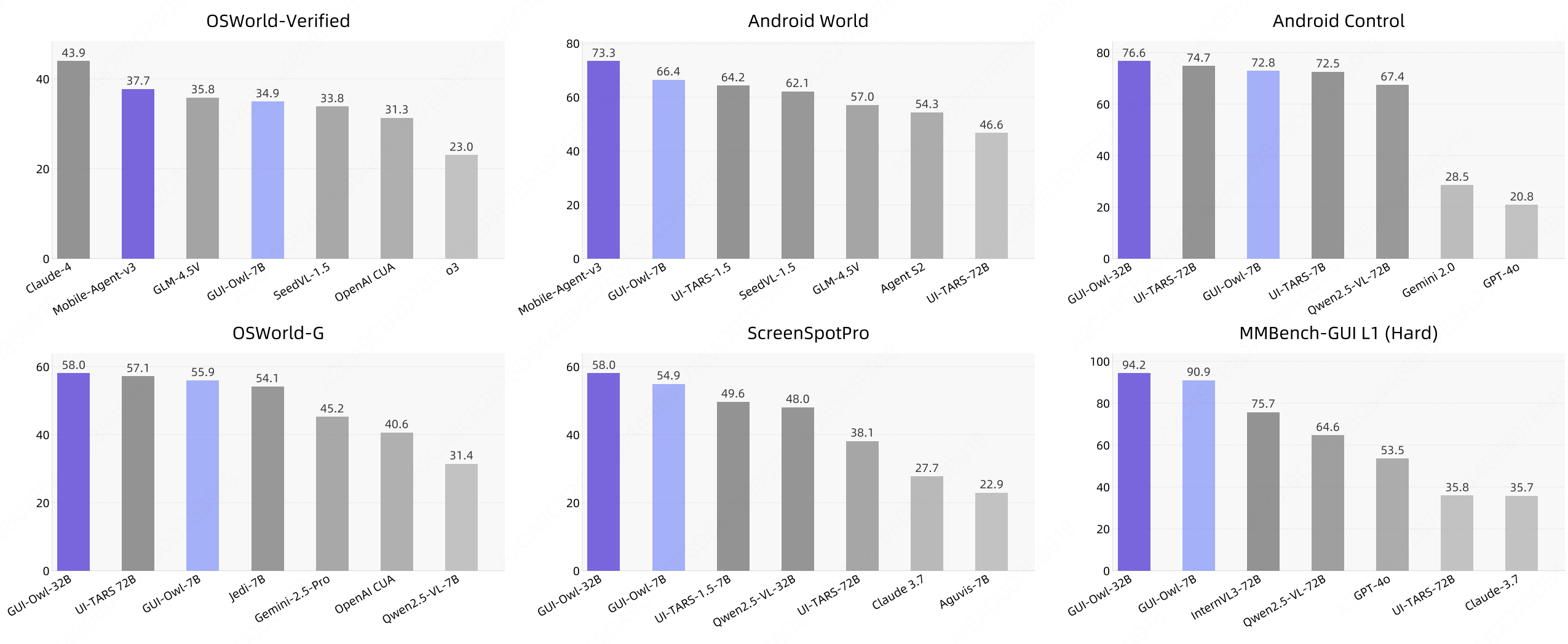
Mobile-Agent-v3: Fundamental Agents for GUI Automation
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, Jitong Liao, Qi Zheng, Fei Huang, Jingren Zhou, Ming Yan
[Paper] |
- A foundation-agent framework for mobile GUI automation that unifies perception, planning, and execution roles, achieving strong performance across long-horizon real-device tasks.
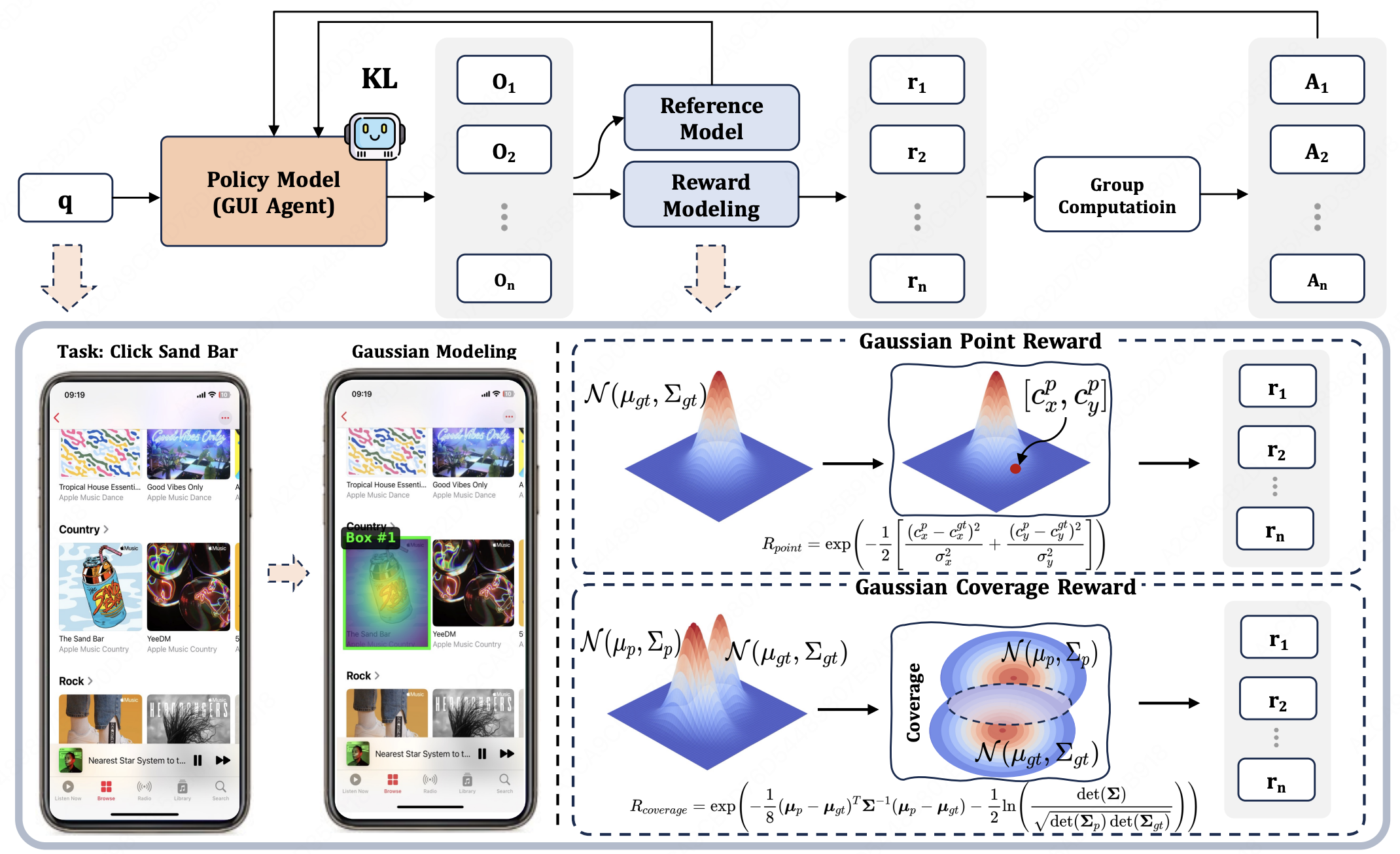
GUI-G²: Gaussian Reward Modeling for GUI Grounding
Fei Tang, Zhangxuan Gu, Zhengxi Lu, Xuyang Liu, Shuheng Shen, Changhua Meng, Wen Wang, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, Yueting Zhuang
[Paper] |
- Replaces binary hit/miss rewards with a Gaussian reward field over click coordinates, providing smoother gradients and substantially improving GUI grounding accuracy under RL.

UI-Copilot: Advancing Long-Horizon GUI Automation via Tool-Integrated Policy Optimization
Zhengxi Lu, Fei Tang, Guangyi Liu, Kaitao Song, Xu Tan, Jin Ma, Wenqi Zhang, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen
[Paper] |
- Tool-integrated policy optimization that lets GUI agents call auxiliary tools mid-trajectory, extending effective horizon and credit assignment for long, multi-screen workflows.
- TMLR 2026 LLM-Powered GUI Agents in Phone Automation: Surveying Progress and Prospects, Guangyi Liu, Pengxiang Zhao, Liang Liu, Yaxuan Guo, Han Xiao, Weifeng Lin, Yuxiang Chai, Yue Han, Shuai Ren, Hao Wang, Xiaoyu Liang, Wenhao Wang, Tianze Wu, Linghao Li, Hao Wang, Guanjing Xiong, Zhengxi Lu, Siheng Chen, Yong Liu, Hongsheng Li
- ACL 2026 Findings LearnAct: Few-Shot Mobile GUI Agent with a Unified Demonstration Benchmark, Guangyi Liu, Pengxiang Zhao, Liang Liu, Zhiming Chen, Yuxiang Chai, Shuai Ren, Hao Wang, Zhengxi Lu, Shibo He, Wenchao Meng
- AAAI 2026 Test-Time Reinforcement Learning for GUI Grounding via Region Consistency, Yong Du, Yuchen Yan, Fei Tang, Zhengxi Lu, Chang Zong, Weiming Lu, Shengpei Jiang, Yongliang Shen
- ACL 2026 MAS-Bench: A Unified Benchmark for Shortcut-Augmented Hybrid Mobile GUI Agents, Pengxiang Zhao, Guangyi Liu, Yaozhen Liang, Weiqing He, Zhengxi Lu, Yuehao Huang, Yaxuan Guo, Kexin Zhang, Hao Wang, Liang Liu, Yong Liu
- CVPR 2026 GUI-SAGE: Enhancing GUI Automation with Self-Explanatory Learning, Fei Tang, Zhangxuan Gu, Zhengxi Lu, Shangzhan Zhang, Zhengwen Zeng, Shuheng Shen, Changhua Meng, Yuchen Yan, Wenqi Zhang, Yongliang Shen, Weiming Lu, Yueting Zhuang.
- ECCV 2026 Label-free GUI Grounding via Confidence-guided Negative Reinforcement Learning, Zhengxi Lu, et al.
- ACMMM 2026 MemGUI-Bench: Benchmarking Memory of Mobile GUI Agents in Dynamic Environments, Guangyi Liu, Pengxiang Zhao, Yaozhen Liang, Qinyi Luo, Shunye Tang, Yuxiang Chai, Weifeng Lin, Han Xiao, WenHao Wang, Siheng Chen, Zhengxi Lu, Gao Wu, Hao Wang, Liang Liu, Yong Liu
- Preprint KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation, Tongbo Chen, Zhengxi Lu, …, Yongliang Shen
- Preprint UI-Zoomer: Uncertainty-Driven Adaptive Zoom-In for GUI Grounding, Fei Tang, Bofan Chen, Zhengxi Lu, Tongbo Chen, Songqin Nong, Tao Jiang, Wenhao Xu, Weiming Lu, Jun Xiao, Yueting Zhuang, Yongliang Shen
- Preprint GUI-CIDER: Mid-training GUI Agents via Causal Internalization and Density-aware Exemplar Reselection, Zheng Wu, Chengcheng Han, Zhengxi Lu, Tianjie Ju, Yanyu Chen, Qi Gu, Xunliang Cai, Zhuosheng Zhang
🎨 Multimodal AI
- ICLR 2025 / AI4Drug @ NIPS’24 ProtPainter: Draw or Drag Protein via Topology-guided Diffusion, Zhengxi Lu, Shizhuo Cheng, Yuru Jiang, Yan Zhang, Min Zhang
- Preprint M³-Verse: A “Spot the Difference” Challenge for Large Multimodal Models, Kewei Wei, Bocheng Hu, Jie Cao, Xiaohan Chen, Zhengxi Lu, Wubing Xia, Weili Xu, Jiaao Wu, Junchen He, Mingyu Jia, Ciyun Zhao, Ye Sun, Yizhi Li, Zhonghan Zhao, Jian Zhang, Gaoang Wang
🎖 Honors and Awards
- Second-Class Scholarship of Zhejiang University, 2021, 2022, 2023.
📖 Educations
- 2020.09 - 2024.06: B.E student at Chu Kochen Honors College, Zhejiang University (浙江大学竺可桢学院).
- 2024.09 - now: Ph.D candidate at REAL Lab, Zhejiang University.
💬 Misc
- Invited Talks:
- 2026.5.24: I gave a talk about skills invited by ZJU AI Talk. Link.
- Reviewers:
- 2025: ACMMM 2025, AAAI 2026, ICLR 2026.
- 2026: CVPR 2026, ECCV 2026, Nuerips 2026.
💻 Internships
- 2025.03 - 2025.06: Research Intern at Vivo AI Lab, advised by Liang Liu.
- 2025.06 - 2025.11: Research Intern at Alibaba Tongyi Lab, advised by Haiyang Xu and Ming Yan.
- 2026.03 - 2026 (now): Beidou Research Intern at Meituan Longcat Team, advised by Qi Gu.